Golang-数组与切片常见错误及陷阱
nil切片、空切片、零切片
零切片
var s = make([]int, 10)
fmt.Println(s)
------------
[0 0 0 0 0 0 0 0 0 0]
表示底层数组的二进制内容都是零
「空切片」和 「nil 切片」
var s1 []int
var s2 = []int{}
var s3 = make([]int, 0)
// new 函数返回是指针类型,所以需要使用 * 号来解引用
var s4 = *new([]int)
fmt.Println(len(s1), len(s2), len(s3), len(s4))
fmt.Println(cap(s1), cap(s2), cap(s3), cap(s4))
fmt.Println(s1, s2, s3, s4)
----------------
0 0 0 0
0 0 0 0
[] [] [] []
上面这四种形式从输出结果上来看,似乎一摸一样,没区别。但是实际上是有区别的,我们要讲的两种特殊类型「空切片」和「 nil 切片」,就隐藏在上面的四种形式之中。
var s1 []int
var s2 = []int{}
var s3 = make([]int, 0)
var s4 = *new([]int)
var a1 = *(*[3]int)(unsafe.Pointer(&s1))
var a2 = *(*[3]int)(unsafe.Pointer(&s2))
var a3 = *(*[3]int)(unsafe.Pointer(&s3))
var a4 = *(*[3]int)(unsafe.Pointer(&s4))
fmt.Println(a1)
fmt.Println(a2)
fmt.Println(a3)
fmt.Println(a4)
---------------------
[0 0 0]
[824634199592 0 0]
[824634199592 0 0]
[0 0 0]
其中输出为 [0 0 0] 的 s1 和 s4 变量就是「 nil 切片」,s2 和 s3 变量就是「空切片」。824634199592 这个值是一个特殊的内存地址,所有类型的「空切片」都共享这一个内存地址。
用图形来表示「空切片」和「 nil 切片」如下

空切片指向的 zerobase 内存地址是一个神奇的地址,从 Go 语言的源代码中可以看到它的定义
//// runtime/malloc.go
// base address for all 0-byte allocations
var zerobase uintptr
// 分配对象内存
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
...
if size == 0 {
return unsafe.Pointer(&zerobase)
}
...
}
//// runtime/slice.go
// 创建切片
func makeslice(et *_type, len, cap int) slice {
...
p := mallocgc(et.size*uintptr(cap), et, true)
return slice{p, len, cap}
}
最后一个问题是:「 nil 切片」和 「空切片」在使用上有什么区别么?
答案是完全没有任何区别!No!不对,还有一个小小的区别!请看下面的代码
package main
import "fmt"
func main() {
var s1 []int
var s2 = []int{}
fmt.Println(s1 == nil)
fmt.Println(s2 == nil)
fmt.Printf("%#v\n", s1)
fmt.Printf("%#v\n", s2)
}
-------
true
false
[]int(nil)
[]int{}
「空切片」和「 nil 切片」有时候会隐藏在结构体中,这时候它们的区别就被太多的人忽略了,下面我们看个例子
type Something struct {
values []int
}
var s1 = Something{}
var s2 = Something{[]int{}}
fmt.Println(s1.values == nil)
fmt.Println(s2.values == nil)
--------
true
false
可以发现这两种创建结构体的结果是不一样的!
「空切片」和「 nil 切片」还有一个极为不同的地方在于 JSON 序列化
type Something struct {
Values []int
}
var s1 = Something{}
var s2 = Something{[]int{}}
bs1, _ := json.Marshal(s1)
bs2, _ := json.Marshal(s2)
fmt.Println(string(bs1))
fmt.Println(string(bs2))
---------
{"Values":null}
{"Values":[]}
Ban! Ban! Ban! 它们的 json 序列化结果居然也不一样!
数组与切片有什么区别
slice 的底层数据是数组,slice 是对数组的封装,它描述一个数组的片段。两者都可以通过下标来访问单个元素。
数组是定长的,长度定义好之后,不能再更改。在 Go 中,数组是不常见的,因为其长度是类型的一部分,限制了它的表达能力,比如 [3]int 和 [4]int 就是不同的类型
而切片则非常灵活,它可以动态地扩容。切片的类型和长度无关。
数组就是一片连续的内存, slice 实际上是一个结构体,包含三个字段:长度、容量、底层数组。
// runtime/slice.go
type slice struct {
array unsafe.Pointer // 元素指针
len int // 长度
cap int // 容量
}
slice 的数据结构如下:
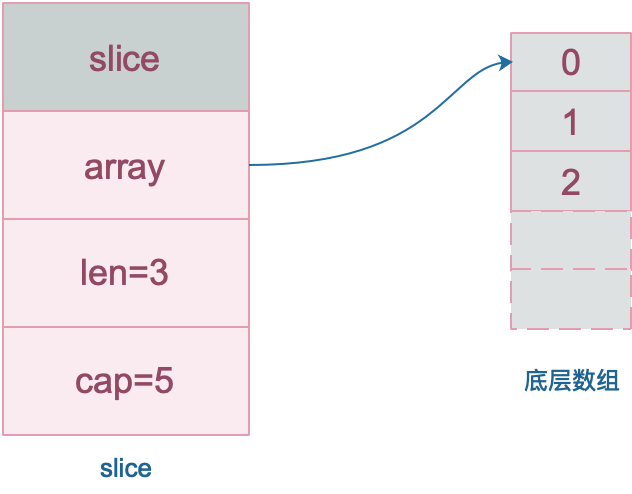
注意,底层数组是可以被多个 slice 同时指向的,因此对一个 slice 的元素进行操作是有可能影响到其他 slice 的。
【引申1】 [3]int 和 [4]int 是同一个类型吗?
不是。因为数组的长度是类型的一部分,这是与 slice 不同的一点。
【引申2】 下面的代码输出是什么?
说明:例子来自雨痕大佬《Go学习笔记》第四版,P43页。这里我会进行扩展,并会作图详细分析。
package main
import "fmt"
func main() {
slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := slice[2:5]
s2 := s1[2:6:7]
s2 = append(s2, 100)
s2 = append(s2, 200)
s1[2] = 20
fmt.Println(s1)
fmt.Println(s2)
fmt.Println(slice)
}
结果:
[2 3 20]
[4 5 6 7 100 200]
[0 1 2 3 20 5 6 7 100 9]
s1 从 slice 索引2(闭区间)到索引5(开区间,元素真正取到索引4),长度为3,容量默认到数组结尾,为8。 s2 从 s1 的索引2(闭区间)到索引6(开区间,元素真正取到索引5),容量到索引7(开区间,真正到索引6),为5。
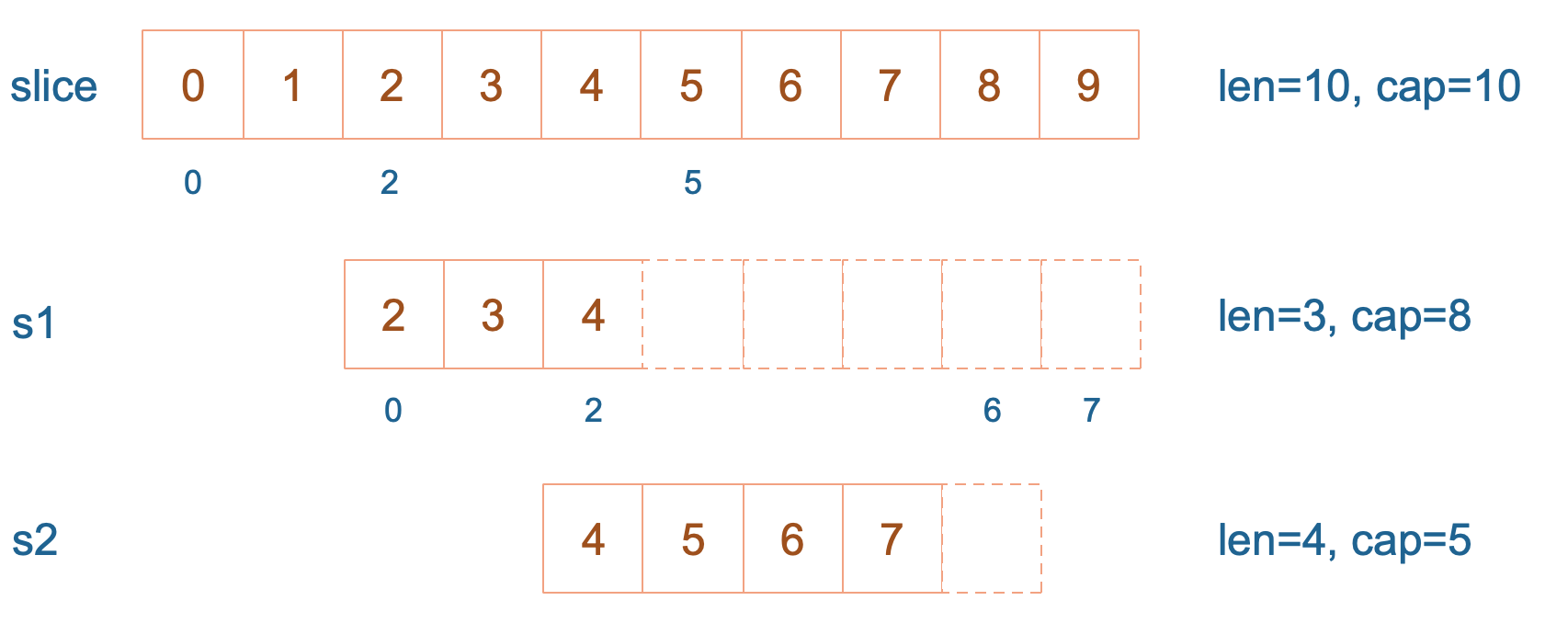
接着,向 s2 尾部追加一个元素 100:
s2 = append(s2, 100)
s2 容量刚好够,直接追加。不过,这会修改原始数组对应位置的元素。这一改动,数组和 s1 都可以看得到。
再次向 s2 追加元素200:
s2 = append(s2, 100)
这时,s2 的容量不够用,该扩容了。于是,s2 另起炉灶,将原来的元素复制新的位置,扩大自己的容量。并且为了应对未来可能的 append 带来的再一次扩容,s2 会在此次扩容的时候多留一些 buffer,将新的容量将扩大为原始容量的2倍,也就是10了。
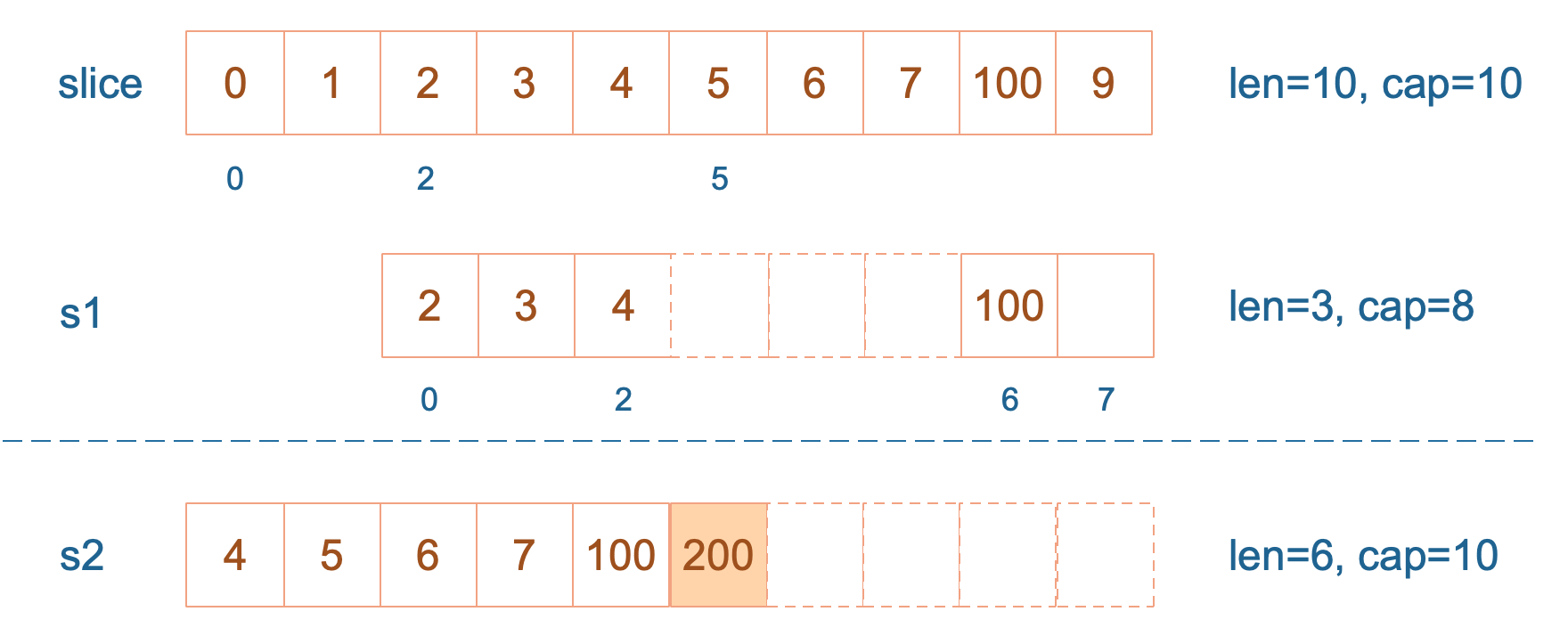
最后,修改 s1 索引为2位置的元素:
s1[2] = 20
这次只会影响原始数组相应位置的元素。它影响不到 s2 了,人家已经远走高飞了。
再提一点,打印 s1 的时候,只会打印出 s1 长度以内的元素。所以,只会打印出3个元素,虽然它的底层数组不止3个元素。
切片作为函数参数
slice 其实是一个结构体,包含了三个成员:len, cap, array。分别表示切片长度,容量,底层数据的地址
当 slice 作为函数参数时,就是一个普通的结构体。其实很好理解:若直接传 slice,在调用者看来,实参 slice 并不会被函数中的操作改变;若传的是 slice 的指针,在调用者看来,是会被改变原 slice 的。
值得注意的是,不管传的是 slice 还是 slice 指针,如果改变了 slice 底层数组的数据,会反应到实参 slice 的底层数据。为什么能改变底层数组的数据?很好理解:底层数据在 slice 结构体里是一个指针,尽管 slice 结构体自身不会被改变,也就是说底层数据地址不会被改变。 但是通过指向底层数据的指针,可以改变切片的底层数据,没有问题。
通过 slice 的 array 字段就可以拿到数组的地址。在代码里,是直接通过类似 s[i]=10 这种操作改变 slice 底层数组元素值。
另外,值得注意的是,Go 语言的函数参数传递,只有值传递,没有引用传递。
来看一个代码片段:
package main
func main() {
s := []int{1, 1, 1}
f(s)
fmt.Println(s)
}
func f(s []int) {
// i只是一个副本,不能改变s中元素的值
/*for _, i := range s {
i++
}
*/
for i := range s {
s[i] += 1
}
}
运行一下,程序输出:
[2 2 2]
果真改变了原始 slice 的底层数据。这里传递的是一个 slice 的副本,在 f 函数中,s 只是 main 函数中 s 的一个拷贝。在f 函数内部,对 s 的作用并不会改变外层 main 函数的 s。
要想真的改变外层 slice,只有将返回的新的 slice 赋值到原始 slice,或者向函数传递一个指向 slice 的指针。我们再来看一个例子:
package main
import "fmt"
func myAppend(s []int) []int {
// 这里 s 虽然改变了,但并不会影响外层函数的 s
s = append(s, 100)
return s
}
func myAppendPtr(s *[]int) {
// 会改变外层 s 本身
*s = append(*s, 100)
return
}
func main() {
s := []int{1, 1, 1}
newS := myAppend(s)
fmt.Println(s)
fmt.Println(newS)
s = newS
myAppendPtr(&s)
fmt.Println(s)
}
运行一下,程序输出:
[1 1 1]
[1 1 1 100]
[1 1 1 100 100]
myAppend 函数里,虽然改变了 s,但它只是一个值传递,并不会影响外层的 s,因此第一行打印出来的结果仍然是 [1 1 1]。
而 newS 是一个新的 slice,它是基于 s 得到的。因此它打印的是追加了一个 100 之后的结果: [1 1 1 100]。
最后,将 newS 赋值给了 s,s 这时才真正变成了一个新的slice。之后,再给 myAppendPtr 函数传入一个 s 指针,这回它真的被改变了:[1 1 1 100 100]。
参考
深度解析 Go 语言中「切片」的三种特殊状态 Go 程序员面试笔试宝典-数组与切片 Go 程序员面试笔试宝典-切片作为函数参数